張镎視角 亞馬遜云科技無服務器技術如何賦能大數據分析與數據處理服務

在當今數據驅動的商業環境中,企業對于快速、靈活且經濟高效的數據處理與分析需求日益迫切。亞馬遜云科技(Amazon Web Services, AWS)憑借其先進的無服務器(Serverless)技術棧,正在深刻變革大數據分析的實踐方式,為數據處理服務注入了前所未有的敏捷性與可擴展性。
無服務器計算的核心在于將基礎設施管理的責任完全移交給云服務商,開發者得以專注于業務邏輯與代碼本身。在大數據領域,這一范式消除了傳統架構中集群規劃、節點配置、容量預估與運維管理的復雜性。用戶無需預置或管理服務器,只需按實際消耗的計算與存儲資源付費,實現了成本與效率的極致優化。
亞馬遜云科技為大數據分析提供了全面的無服務器服務組合。Amazon Athena 作為交互式查詢服務,允許用戶使用標準 SQL 直接分析 Amazon S3 中的數據,無需進行任何數據加載或轉換。其無服務器特性意味著查詢能力可瞬間彈性擴展,輕松應對從 GB 到 PB 級的數據規模。結合 AWS Glue,一個全托管的提取、轉換和加載(ETL)服務,企業可以自動化地發現、準備和集成來自多個來源的數據,為分析構建高質量的數據湖。
在流數據處理方面,Amazon Kinesis Data Analytics 提供了無服務器方式實時處理和分析流數據的能力。開發人員可以編寫標準 SQL 或使用 Apache Flink(通過 Amazon Managed Service for Apache Flink)構建復雜的流處理應用,實時獲取洞察并驅動即時決策。而 AWS Lambda 作為函數即服務(FaaS)的典范,更是將事件驅動的無服務器架構融入數據處理流水線的各個角落,能夠響應數據到達、狀態變更等事件,觸發細粒度的數據處理任務。
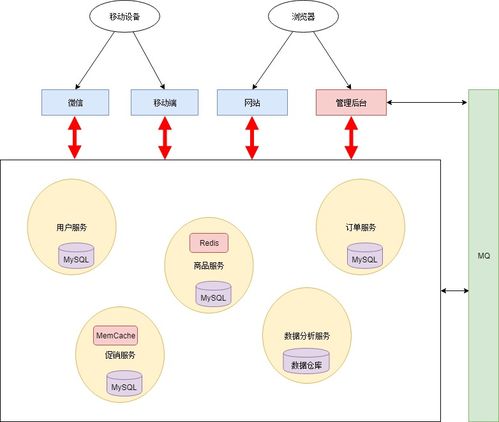
亞馬遜云科技的無服務器大數據服務,通過深度集成,形成了強大的協同效應。例如,一個典型的數據處理管道可能是:數據源產生的數據流被 Amazon Kinesis Data Streams 攝入;AWS Lambda 函數被觸發進行初步的數據清洗或格式化;處理后的數據持久化存儲到 Amazon S3 數據湖中;AWS Glue 爬蟲自動更新數據目錄;業務分析師隨即通過 Amazon Athena 進行即席查詢;復雜的數據轉換與建模任務由 Amazon Redshift Serverless(一種無服務器數據倉庫)來承載,提供海量數據的并發分析能力。
這種無服務器架構帶來了多重顯著優勢:
- 敏捷性與速度:企業可以快速構建和部署數據分析應用,將想法轉化為產出的時間從數月縮短至數天甚至數小時。
- 極致的彈性與可擴展性:服務自動按需擴展,從容應對不可預測或劇烈波動的工作負載,無需為峰值流量過度配置資源。
- 成本優化:遵循“用多少付多少”的模型,企業只為實際使用的資源付費,閑置成本為零,使得大數據分析的門檻大幅降低。
- 降低運維負擔:團隊無需管理底層基礎設施,可以將寶貴的精力專注于數據價值挖掘與業務創新。
以張镎所代表的行業專家視角來看,亞馬遜云科技的無服務器技術正通過其全托管、高彈性、按需付費的特性,重新定義大數據分析與數據處理的未來。它不僅簡化了技術復雜性,更關鍵的是賦能了各類規模的企業,使其能夠以更低的成本和更高的效率,從海量數據中提取關鍵洞察,驅動智能決策與業務增長。無服務器化已成為構建現代、高效、可持續大數據平臺的關鍵路徑。
如若轉載,請注明出處:http://m.nxbww.cn/product/27.html
更新時間:2026-01-09 12:46:09